With 4th generation AMD (Genoa) systems widely available now both on-prem and in the cloud engineers have been adopting them for their CFD workloads. On the cloud AWS offers 4th generation AMD with HPC7a, and on Azure it is HBv4.
One continued theme we see with folks trying AMD based systems on their own, is they are not getting the performance they expect by taking a stock machine with no tuning and run their CAE applications without change. This is not new and it was a similar issue we saw when AMD EPYC 3rd generation first came on the seen a few years ago, see this post from 2021 on AMD tuning with Abaqus
The AMD architecture does require to do some work to be done to get the maximum performance the AMD architecture is capable of with your CAE applications. This post is to go over in a bit more detail one tuning that is good for memory bandwidth limited CFD applications. First, we need to go over some chip details to understand what this tuning is about.
A look at 4th Generation AMD (Genoa) Chiplet Design
Below is a logical diagram of a single 96-core AMD 4th generation processor that has 12 Chiplet Dies (CCD’s) with each CCD having 8 zen4 cores.
What is a CCD? You can think of it like a processor with 8 cores that share a large L3 memory cache. The CCD’s are essentially “glued” together to build really high core count processors.
Imagine you are running a 12 core CFD application on this configuration. Note that CFD codes are often memory bandwidth bound, which means the speed of memory access is very important. If the operating system decides to pack the 12 cores pack across two of the 8-core “chiplets”, they are competing for the lane to memory with each other, and sharing their cache, which can results in reduced performance compared the optimal case.
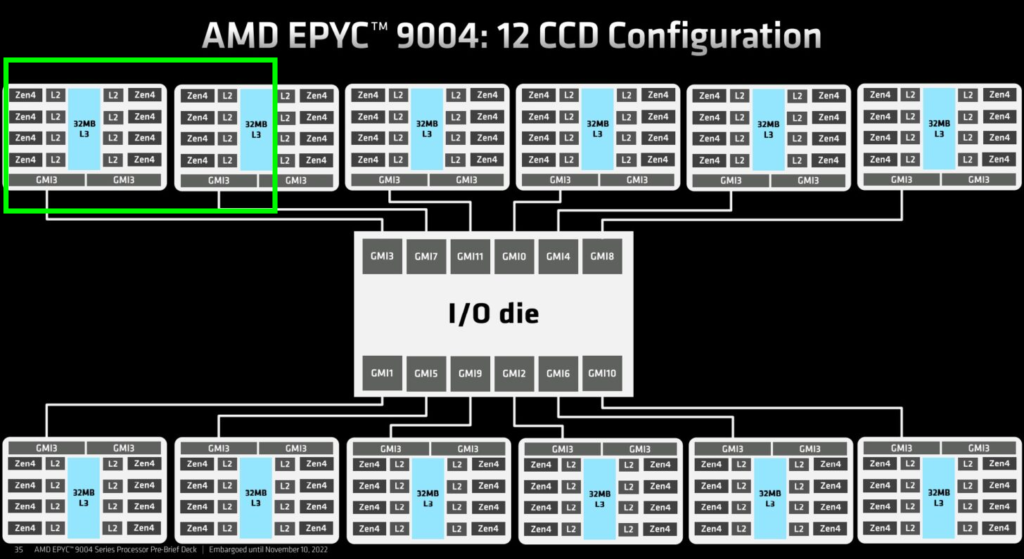
The optimal case for a 12 core CFD run, is to use only 1 core of the 8, on each of the 12 chiplets. That one core gets the entire CCD L3 cache to itself, and is not competing with cores on the chiplets for memory bandwidth. This is pictured below with green being the cores to leave enabled.
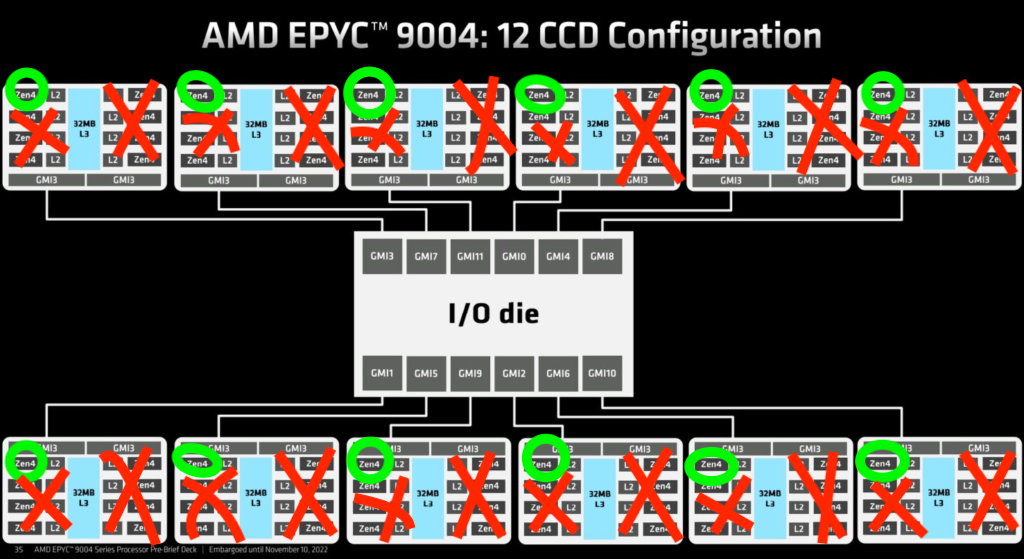
In Linux, the simplest method to guarantee processes use the most optimal cores is to disable specific cores to leave the optimal cores running based on your workload. There are other methods to try and do the correct pinning, but this is simplest. TotalCAE for example, dynamically handles enabling and disabling the proper cores in our scheduler to optimize each job.
This sort of tuning on AMD is required both on-prem, and on cloud in most cases. (See the exception on 4th generation hpc7a instances on AWS later in this blog post).
Performance Increase From Strategic Core Disabling
Running some standard CFD benchmarks on lower core counts (25%, 50%, 75% of cores) with the correct cores disable can see a 25% increase in performance compared to running the same core count with all CPU cores enabled.
This is a significant speedup just from this one optimization.

Interesting Feature of Azure HBv4 with Core Disabling
Azure has released their 4th Generation AMD Genoa-X with SKU’s below.
We have been asked why the 24, 48, and 96 core versions of this instance are the same price as the 176 core instance. What Azure is doing behind the scenes is disabling the cores on your behalf, to free you from needing to do this particular tuning described in the blog post.
So if you want to run a 24 core job, pick the Standard+HB176-24rs_v4 which is essentially large instance with the cores disabled properly to maximize your application performance. The reason this instance does not have all the CPU cores exposed, is Azure also reserves some cores for their use behind the scenes.
Interesting Feature of AWS HPC7a with Core Disabling
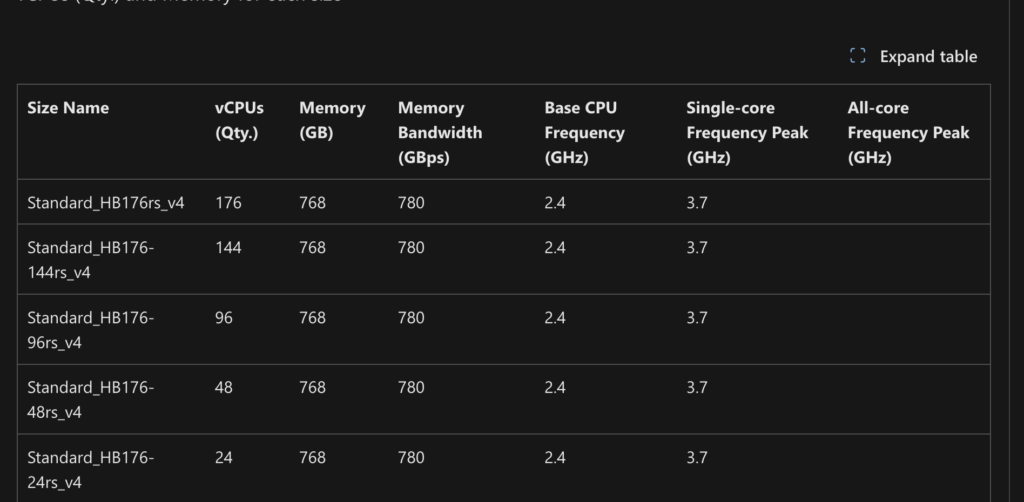
AWS has released their 4th Generation AMD Genoa instances with the HPC7a family SKU’s below.
We have been asked why the 24, 48, and 96 core versions of this instance are the same price as the 192 core instance. What AWS is doing behind the scenes is disabling the cores on your behalf, to free you from needing to do this particular tuning described in the blog post. So if you want to run a 96 core job, pick the hpc7a.48xlarge which is essentially hpc7a.96xlarge with 1/2 the cores disabled properly to maximize your application performance. In previous 3rd generation AMD instances such as hpc6a, you needed to do the optimizations yourself.

hpc7a disables the optimal cores for you based on the instance size.
Key Takeaway
AMD EPYC requires some tuning to get performance out of many CAE applications. However complete system tuning of the OS, using your scheduler to optimize each workload, tuning middleware libraries like MPI, and tuning in CAE/CFD application itself can dramatically reduce your runtimes.
TotalCAE systems come with these types of optimizations and recommendations baked in “out of the box” on our managed HPC clusters and managed cloud systems, and the cloud vendors have now offered optimized instance sizes based on your core count, so you don’t have to be a tuning expert to get performance gains, performance is made simple with TotalCAE.